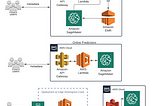
Shabaz PatelinArtificial Intelligence in PracticeArchitecting the Right AI System for your Problem — Part 1In Part 1 of this series, we explore the framework any Data Science or AI leader will need to start with to determine the right toolset.4 min read·Jan 19, 2021----
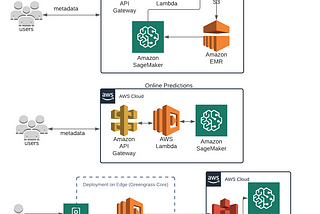
Shabaz PatelinArtificial Intelligence in PracticeChallenges in operationalizing a machine learning systemThe goal of this blog is to cover the key topics to consider in operationalizing machine learning and to provide a practical guide for…5 min read·Oct 25, 2020----